Despite extensive use of distributed databases and filesystems in data-driven workflows, there remains a persistent need to rapidly read text files on single machines. Surprisingly, most modern text file readers fail to take advantage of multi-core architectures, leaving much of the I/O bandwidth unused on high performance storage systems. Introduced here, ParaText, reads text files in parallel on a single multi-core machine to consume more of that bandwidth. The alpha release includes a parallel Comma Separated Values (CSV) reader with Python bindings.
For almost 50 years, CSV has been the format of choice for tabular data. Given the ubiquity of CSV and the pervasive need to deal with CSV in real workflows — where speed, accuracy, and fault tolerance is a must — we decided to build a CSV reader that runs in parallel.
We conducted extensive benchmarks of ParaText against 7 CSV readers and 5 binary readers. Please refer to our benchmarking whitepaper for more details. In our tests, ParaText can load a CSV file from a cold disk at a rate of 2.5 GB/second and 4.2 GB/second out-of-core from a warm disk. ParaText can parse and perform out-of-core computations on a 5 TB CSV file in under 30 minutes.
Why CSV?
The simplicity of CSV is enticing. CSV is conceptually easy-to-parse. It is also human readable. Spreadsheet programs and COBOL-era legacy databases can at least write CSV. Indeed, it has become widely used to exchange tabular data. Unfortunately, the RFC standard is so loosely followed in practice that malformed CSV files proliferate. The format lacks a universally accepted schema so even “proper” CSV files may have ambiguous semantics that each application may interpret differently.
In spite of CSV’s issues, the community needs robust tools to process CSV data. We set out to build a fast, memory-efficient, generic multi-core text reader. Our CSV reader is the first to make use of this infrastructure.
Highlights of Release & Benchmarks
The ParaText CSV reader supports integer, floating-point, text, and categorical data types. The narrowest bit depth is always used to save memory. Text fields can span multiple lines. A compact categorical encoding maps repeated strings to integers to keep the memory footprint low.
ParaText can load a CSV file into a Pandas DataFrame in one line of code.
df = paratext.load_csv_to_pandas(filename)
A ParaText column iterator can be used to populate many kinds of data structures (e.g. Python dictionaries, Pandas DataFrames, Dato SFrames, or Spark DataFrames.)
for name, values in paratext.load_csv_as_iterator(filename, expand=True, forget=True):
print "column name: ", name
print "column data: ", values
Here, the expand keyword forces ParaText to use strings to represent categories, rather than integers. The forget causes the iterator to free each column’s memory from the parser after it has been visited. This avoids doubling the memory usage.
In our benchmarks, we demonstrated ParaText’s speed, efficiency, benchmarking whitepaper for more details.
Data
The files used in our benchmarks ranged in size from 21 MB to 5.076 TB. The whitepaper describes the characteristics of each data set and how to download them.
File sizes for each data set and each format. Binary files are more compact than CSV files.
1. ParaText is fast!
ParaText had a higher throughput than any of the other CSV readers tested, on every dataset tried.

2. ParaText is memory-efficient!
ParaText had the lowest overall memory footprint. Dato SFrame had very low memory usage on text data as long as the data frame stayed in Dato’s kernel. Spark reserves a large heap up-front. It is therefore difficult to make claims about its memory efficiency to better inform how to provision resources for Spark jobs.
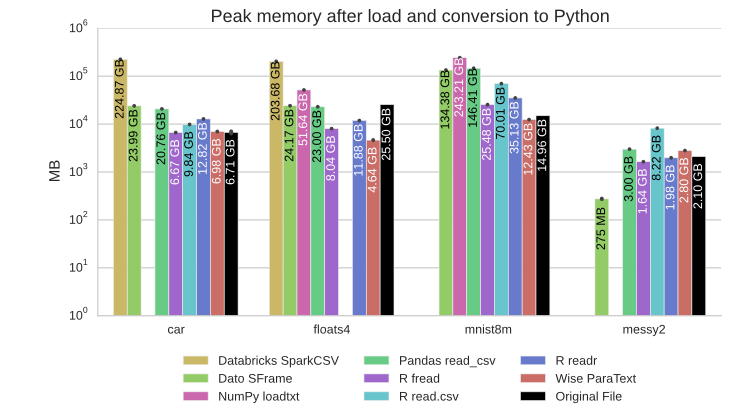
3. ParaText vs. binary: still fast!
Popular binary readers read more compact files without any parsing, type inference, or error checking. As expected, binary readers finish before ParaText on files that are up to 10x smaller.
Binary readers finish before ParaText. However, binary readers process smaller files, column types are well-defined, and error checking is minimal. Pickle is slowest.
However, the binary readers we tested perform significantly below the I/O bandwidth compared to ParaText.

4. Fast conversion of DataFrames
Spark DataFrame, Dato SFrame, and ParaText can convert from their internal representations to a Python object in one line of code. This enhances the interactive experience of the data scientist.
# Spark
df = spark_data_frame.toPandas()
# Dato
df = dato_sframe.to_dataframe()
This conversion is an important part of the data scientist’s interactive experience. ParaText can convert a multi-gigabyte data set in seconds while Spark and Dato take minutes.

5. ParaText is cheaper!
The prorated Amazon Web Services (AWS) costs for Wise ParaText are disproportionately low compared to other methods.

6. ParaText approaches the limits of hardware!
We defined two baseline tasks to establish upper bounds on the throughput of CSV loading: newline counting and out-of-core CSV parsing. ParaText achieves a throughput that is very close to the estimated I/O bandwidth depending on the task.

7. ParaText is Medium Data
ParaText can handle multi-terabyte data sets with ease. In our tests, ParaText and Spark were the only methods that successfully loaded and summed a 1+ TB file on a single machine.

Interested?
Visit GitHub and give ParaText a try. We'd love to hear from you!
We placed strong emphasis on reproducibility. Check out our benchmarking whitepaper for full details.
Dr. Damian Eads is a co-founder of Wise.io and main creator of its core machine learning technologies. He spent a decade as a machine learning researcher at Los Alamos National Laboratory. After his PhD in Computer Science at UC Santa Cruz, he was a visiting scholar at UC Berkeley and later a postdoctoral scholar at Cambridge University.
ps. We’re looking for amazing engineers to help us build out our novel infrastructure to orchestrate massive machine learning pipelines. If you’re the one, get in touch!